Hugging Face has launched the Idefics2 vision-language model.
Hugging Face has launched the Idefics2 vision-language model.

Hugging Face has unveiled Idefics2, a cutting-edge vision-language model designed to excel in processing and generating text responses based on both images and textual input. Idefics2 represents a significant advancement over its predecessor, Idefics1, featuring only eight billion parameters while demonstrating considerable versatility under its open Apache 2.0 license. The model also boasts improved Optical Character Recognition (OCR) capabilities, enhancing its ability to interpret text within images more effectively.
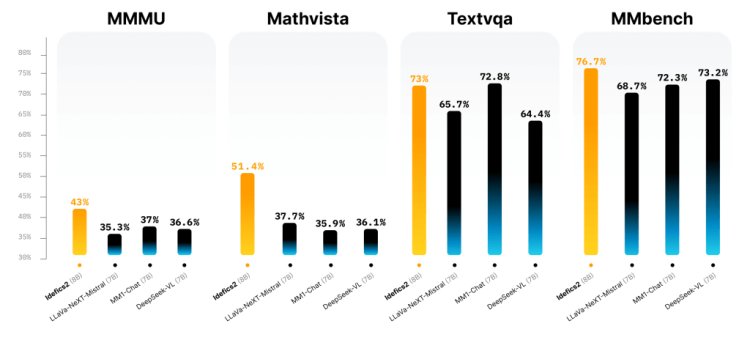
Idefics2 sets new standards in various applications, including visual question answering, image description, story creation from visual content, document information extraction, and conducting arithmetic operations from visual data. Its performance is competitive, holding up against larger models such as LLava-Next-34B and MM1-30B-chat.
A key aspect of Idefics2’s design is its seamless integration with Hugging Face’s Transformers library, facilitating easy fine-tuning across a wide range of multimodal applications. Those interested in exploring the capabilities of Idefics2 can find the model ready for experimentation on the Hugging Face Hub.
The training methodology of Idefics2 incorporates a diverse mix of openly available datasets, which include web documents, image-caption pairs, and OCR data. An innovative addition to its training regimen is 'The Cauldron'—a fine-tuning dataset that combines 50 carefully selected datasets for comprehensive conversational training.
One of the standout features of Idefics2 is its approach to image handling, which preserves the native resolution and aspect ratios of images, moving away from the common practice of resizing in computer vision. This change, along with its advanced OCR features, allows Idefics2 to accurately transcribe and interpret textual content within images and documents, especially enhancing its ability to understand charts and figures.
The architecture of Idefics2 also sees improvements with the introduction of learned Perceiver pooling and MLP modality projection, which enhance the integration of visual features into the language model, thereby boosting overall performance.
With these enhancements, Idefics2 is poised to become a foundational tool for developers and researchers interested in exploring multimodal interactions. Its blend of technical innovations and performance improvements demonstrates the growing potential of combining visual and textual data to create sophisticated, contextually aware AI systems.